
核能是最好的能源选择吗?
撰文 |饮马流花河
出品 | 零碳知识局
上个月在瑞士达沃斯世界经济论坛年会上,OpenAI首席执行官萨姆·奥特曼表示:人工智能行业正在走向能源危机。奥特曼警告说,下一波生成式人工智能系统将消耗比预期更多的能源,而能源系统将难以应对。

无独有偶,在博世全球互联会议上进行的电话问答环节中,最近被提名为诺贝尔和平奖候选人的埃隆·马斯克表示:“芯片短缺可能已经过去了,但人工智能和电动汽车的迅速扩张将导致明年电力和变压器供应出现紧缺。”
马斯克强调了人工智能计算量的指数级增长,“每六个月似乎增加了10倍,尽管这种高速增长显然无法永远持续下去,否则将超过宇宙的质量,“我从未见过任何技术的发展速度比这更快。”埃隆·马斯克表示。
两个人其实说了一个意思,人工智能发展得太快,电不够用了。
生成式人工智能模型离不开芯片的算力支持。进入三月份,英伟达市值一夜涨超2600亿元,市值超2万亿,从侧面印证了AI发展对算力的高需求。
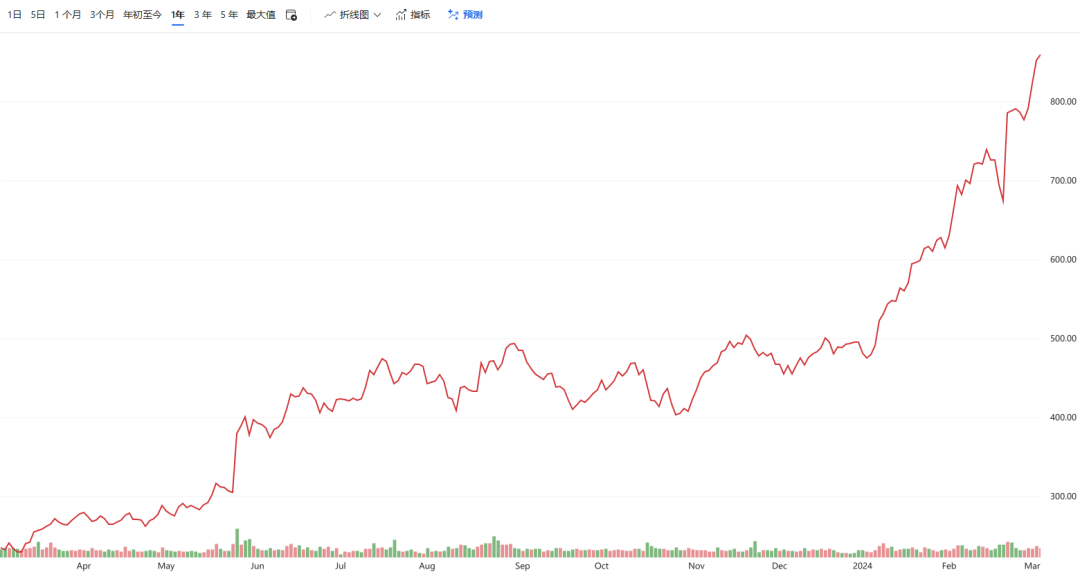
英伟达股价变化
黄仁勋称,对 AI 所依赖的计算能力的需求仍然是极其巨大的,“全球范围内,企业、行业和各国的需求都在激增。”据悉,英伟达的业绩爆发得益于数据中心业务的增长,特别是生成式人工智慧和语言模型的训练和推理的推动。
作为整个ai大潮的算力基础,英伟达的A100和H100GPU去年曾一芯难求,专业人士表示:训练一个类似于GPT—3.5左右的大语言模型大概需要1万张A100芯片,硬件投入就需要20亿元。
算力的运行和生产往往离不开电力,据微软数据中心技术的预测,到2024年底,全球部署的百万量级的H100 GPU将使得英伟达的总耗电量超过亚利桑那州凤凰城的所有家庭用电量,仅次于德克萨斯州休斯敦。
H100 GPU的最大功耗达到700W,以利用率61%计算,每颗GPU每年将消耗约3,740kWh的电力。到2024年底,全球范围内将有350万个H100 GPU投入使用,它们每年将消耗总计13,091.82 GWh的电力。这一天文数字相当于立陶宛等国家的全年耗电量。
不能忽略的是,电力消耗又与碳排放息息相关,可是之前,AI行业的环境和碳排放成本被科技公司淡化和否认。
奥特曼和马斯克两位科技领袖的呐喊不仅揭示了AI行业的能源危机,也引发了全球研究人员、监管机构和行业巨头们对生成式人工智能环境影响的大讨论。
2月1日,马萨诸塞州参议员爱德华·马基领导的美国民主党人提交了《2024年人工智能环境影响法案》。该法案要求美国国家标准与技术研究所与学术界、行业和公民社会合作制定评估人工智能环境影响的标准,预示着对AI行业的环境监管已经箭在弦上。
AI的另一面
大语言模型的开发是一场疯狂的烧钱游戏,纵观人工智能行业的产业链,从基础层的硬件、数据输入计算,到技术层的算法模型开发,再到应用层的商业化落地都需要大量的资金、人力投入。
为了获得更优的智能表现,语言模型逐渐朝着大型化方向发展,投喂的学习数据呈指数级增长,参数也越来越多:GPT-3.5 训练参数为1750亿,GPT-4为1.8 万亿,亚马逊发布的全新大模型Olympus参数高达2万亿,训练和调试的能源损耗将不断攀升。

更强大的GPT-5正在训练中
简单而言,AI越智能,耗能就越多。
例如,来自《焦耳》杂志上的一项研究表明,到2027年,生成式人工智能所消耗的能源能为荷兰大小的国家提供一年的电力,相当于约85-134太瓦时(TWh)。参数更多、功能更为强大的人工智能将给人类的能源供应产生巨大压力。
这意味着在几年内,大型人工智能系统需要的能源量可能将达到整个国家的用能水平,要实现向全面智能时代过渡,甚至建成元宇宙,能源消耗不可估量。
近期发表在《自然》杂志上的一篇文章指出,由生成式人工智能驱动的搜索所消耗的能源是传统网络搜索的四到五倍,OpenAI在加利福尼亚州旧金山创建的聊天机器人ChatGPT已经消耗了33,000个家庭的能源。
此外,生成式人工智能系统需要大量的淡水来冷却其处理器和发电,耗水量是一个无底洞!
在爱荷华州西德莫因市,一个巨大的数据中心群为OpenAI的最先进模型GPT-4提供服务。当地居民的一项诉讼显示,在OpenAI完成对该模型的训练之前的2022年7月,该数据集群使用了该地区约6%的水资源。
加利福尼亚大学河滨分校和德克萨斯大学阿灵顿分校的研究人员在一篇名为《让人工智能更加节水》的论文中发现,用于训练GPT-3所需的清洁淡水量相当于填满核反应堆冷却塔所需的水量。

训练GPT-3耗费的清洁淡水量与其他活动耗水量的对照图
ChatGPT在与用户进行大约25-50个问题的交流时需要“喝”一瓶500毫升的水。
根据公司的环境报告,谷歌和微软准备他们的Bard和必应大语言模型时,两家公司的用水量一年内分别增加了20%和34%。文章称:全球生成式人工智能对水资源的需求到2027年可能达到英国的一半水平。
追踪碳足迹
人工智能产业经常与石油业相提并论:数据,一旦被发掘和精炼,便如同石油,能够转化为极为珍贵的财富。但就像石油一样,大模型训练及其使用所产生的碳排放量触目惊心。
有许多因素决定了人工智能系统的碳排放量,包括模型中的参数数量(业界普遍认为500亿—600亿参数是大模型智能涌现的门槛)、数据中心的电力使用情况、电网碳排放量、电力使用效率,以及电网的碳强度(多少克二氧化碳被释放以产生一千瓦时的电力)。
但由于科技公司对训练数据的披露极为有限,针对大模型碳足迹的研究屈指可数,其中AI初创公司Hugging Face以及马萨诸塞大学阿默斯特分校的两项研究对大模型碳足迹进行了最全面的分析。
马萨诸塞大学阿默斯特分校的研究对几种流行的大型AI模型(Transformer、ELMo、BERT以及GPT-2)的训练过程进行了生命周期碳排放评估。他们将每个模型在单个GPU上训练一天以测量其能耗,再根据模型原论文中记录的训练时间来计算整个训练过程中的总能耗。
研究发现,该过程可能会产生超过626,000磅的二氧化碳等价排放——这几乎是一辆美国汽车在其整个使用寿命内排放量的五倍(包括汽车制造过程)。
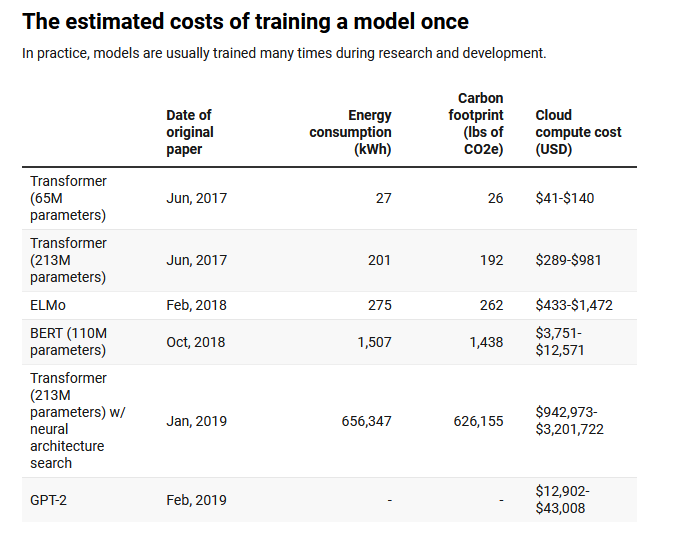
不同参数的生成式大模型一次训练的碳排放、成本、耗电量
来源《麻省理工科技评论》、马萨诸塞大学阿默斯特分校
从图表中可以看出,碳排放与模型的大小成正比。智能模型之所以耗能巨大,正是因为其训练依赖从互联网收集的庞大数据集,训练的参数越多,大模型的性能就越强大,与之对应的算力需求也会成倍增长,使得用于训练的GPU功耗陡然增加,用电量激增。
并且,当采用额外的调节步骤以提升模型最终的准确率时,成本和碳排放将急剧上升。
此外,研究者指出,这还只是开始,实际情况中,人工智能公司更可能从零开始开发新模型或者将现有模型调整至新的数据集,这两种情况都可能需要更多的训练和调节轮次,也意味着更多碳排放。
在实践中,开发和测试一个符合发布标准的模型,需在六个月时间内训练4,789个模型。这一过程产生的二氧化碳当量超过78,000磅。
这意味着大量人工智能开发忽视了研发效率,为追求最优模型结果而不惜大量烧钱,许多能源资源都被浪费了,之所以如此,是因为能够获得充足计算资源的公司和机构能够借此获得竞争优势。
AI初创公司Hugging Face的研究则评估了模型在整个生命周期内的排放量,而不仅仅是大模型训练过程中的排放。这一研究也被斯坦福大学研究机构 HCAI 一年一度的 AI Index 报告所引用。
Hugging Face对其自研的大型语言模型BLOOM进行了整体排放量的估算,包括:在超级计算机上训练模型所消耗的能源总量、制造超级计算机硬件及维持其计算基础架构所需的能源,以及一旦BLOOM发布后的运行能源消耗。同时根据公开数据估算了另外三个热门大模型的碳足迹。
研究发现,四个大语言模型中,GPT3模型的训练耗电量达到了惊人的1287MWH,碳排放502吨,其巨额排放的部分原因是其使用了较旧、效率较低的硬件进行训练。
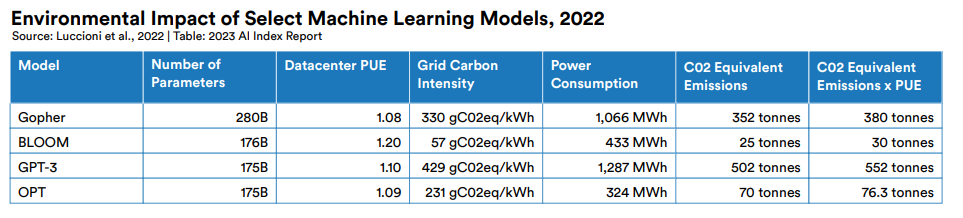
图源:斯坦福大学 AI Index report 2023
这是一个人一生用电量的12倍多。相当于内蒙古(碳排放量全国top1)的人均碳排放的20倍,和腾讯2021年的供应链与自身运营产生的碳排放接近。
当与现实生活做对照时,AI的能耗更加触目惊心。例如,表格中参数最小的BLOOM训练所排放的碳是美国人一年平均碳排放量的1.4倍。是一个乘客从纽约到旧金山的飞机往返行程的25倍。BLOOM训练所消耗的能量足以为普通美国家庭提供41年的电力。
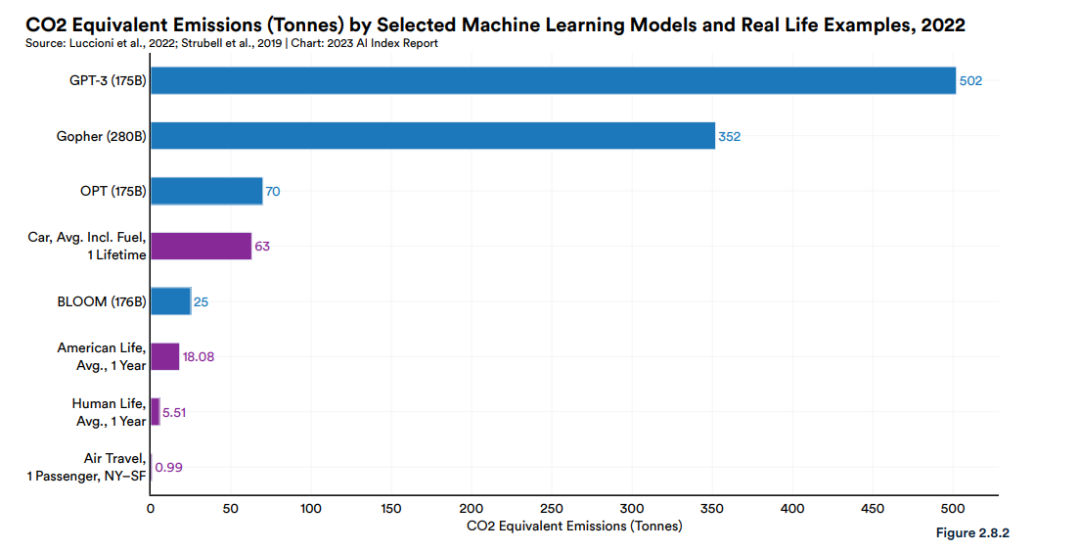
图源:斯坦福大学 AI Index report 2023
Hugging Face的估算结果显示,BLOOM训练过程导致了25吨二氧化碳的排放。然而,当考虑到训练所用计算机设备的制造排放、数据中心等基础设施能耗以及训练完成后实际运行排放等范围三排放时,碳排放量达到了50吨。
在BLOOM推出后,Hugging Face估计使用该模型每天会产生大约19公斤的二氧化碳排放,这与一辆新车行驶大约54英里产生的排放相似。
尽管对于单一模型而言,50吨的二氧化碳排放听起来可能很多——相当于大约60次伦敦至纽约之间的飞行,但与同等大小的其他模型相比,其排放要低很多。
因为BLOOM在一个主要依赖核能的法国超级计算机上进行训练,而核能不会产生二氧化碳排放。
这说明,寻找稳定、清洁的能源供给对于科技巨头们的AI事业极为重要。
谁是能源突破?
高科技企业必须实现绿色转型已经成为全球共识。实际上全球科技巨头很早就意识到,再先进的算力都要在能源面前低下头颅,接受绿色改造。
早在2019年,Amazon就宣布到2024年使用80%的可再生能源,到2030年使用100%可再生电力,到2040年实现零碳排放。亚马逊承诺到2030年,利用电动车和生物燃料实现所有出货量的50% “零碳排放”,Google宣布到2030年实现所有的数据中心和办公领域全部实现无碳能源的供给。
苹果公司走在最前列,其数据中心和Apple store都使用了100%的可再生能源电力。并承诺在2030年之前,会实现供应链和产品100%的碳中和。
然而无论是可再生能源还是化石能源,在稳定度和能量密度方面均不如核能,这种差距在人工智能高速发展、能耗巨大的未来会更加明显。
与其他巨头青睐可再生能源不同,OpenAI 和微软押注的便是核聚变。
2021年,奥特曼向美国私有核聚变公司Helion Energy投资了3.75亿美元。
Helion Energy声称正在建设世界上第一座核聚变发电厂。
目前,该公司已经签署了一项电力购买协议,未来几年将用核聚变为微软提供能源。

Helion Energy核聚变设备
该协议将使世界上第一台商业核聚变发电机接入华盛顿的电网。其目标是产生至少50兆瓦的电力,比美国头两个海上风电场装机容量还多42兆瓦。
奥特曼告诉路透社,“没有能源的突破,就无法实现目标。”他说,“这激励我们更多地投资于核聚变技术。”
但大多数专家认为,核聚变不会对到2050年前减少碳排放以应对气候危机的关键目标做出重大贡献。
Helion公司最乐观的估计是,到2029年,其将产生足以为40,000个美国家庭提供能源的能量,目前来看,远水解不了近渴。
OpenAI背后的微软一直是核能的拥趸。该公司在第28届联合国气候变化大会上发布了关于先进核能和核聚变能源的政策简报,表示先进核能和核聚变技术潜力巨大,它们可以提供安全、可靠、可扩展的无碳电力,并与可再生能源互相补充,满足世界各地不同的能源需求。
技术路线上,微软更青睐小型模块化反应堆(SMR),因其占地面积较小,安装灵活,无需频繁地更换燃料,比大型动力反应堆更便宜;SMR不仅适用于传统的发电厂,还特别适合部署于能源需求日益增长的数据中心。
2023年12月,微软聘任了两位核能相关经理,负责领导SMR和微反应器集成的技术评估,旨在利用核能为微软云和人工智能所在的数据中心提供动力。
国际原子能机构资料显示:SMR 燃料需求少,与传统发电厂1到2年换料周期相比,基于 SMR 的发电厂可能需要较少的换料频率,每 3 到 7 年一次。一些 SMR 设计可在不加料的情况下运行长达 30 年。

中核集团旗下中国核电投资控股中核海南多用途模块式小型堆科技示范工程“玲龙一号”
SMR 还可以与混合能源系统中的可再生能源配对并提高其效率。这些特点使 SMR 在清洁能源转型中发挥关键作用,同时也帮助各国实现可持续发展目标(SDG)。
可以说SMR完美符合高能量密度、灵活安装、便宜等能源需求。中、英、美均在紧密布局。
但是与传统反应堆相比,SMR需要更多的高浓缩铀燃料“HALEU”,不巧的是,俄罗斯是HALEU的全球主要供应国。
此外,美国在SMR方面审批手续极为繁杂,目前还没有一项SMR项目投入正式建设,直到2022年8月,美国核管理委员会(NRC)才审查通过了纽斯凯尔电力公司(NuScale Power)的一项SMR设计,这是NRC认证的首个SMR设计。
然而,该SMR项目却于2023年11月8日被宣布终止建设,原因是大多数潜在用户不愿承担开发此类项目的风险。
据美国媒体Axios报道,微软已经与加拿大公用事业公司安大略发电公司(Ontario Power Generation)达成协议,购买清洁能源积分,该公司有望成为北美第一家部署SMR的公用事业公司。
目前绝大多数SMR还处于概念设计阶段,技术路线、安全、审批、公众接受度均需要时间的磨合。
发表评论 取消回复